Smart Reddit Search (RAG)
A smart reddit agentic AI built using n8n that searches for specific posts from a vector store.
Summary
Smart Reddit Search is an AI-powered retrieval system that searches specific Reddit discussions using Retrieval-Augmented Generation (RAG). Instead of relying solely on an LLM’s internal knowledge, the system retrieves relevant Reddit posts using Apify, processes them into searchable embeddings, and generates responses grounded in actual community discussions.
The entire workflow is orchestrated using n8n, combining web search, data processing, vector search, and large language models into a single automated pipeline.
The Problem
Large language models often struggle with questions that depend on real user experiences or rapidly changing information. While Reddit contains valuable discussions, manually searching through multiple threads is slow and often produces inconsistent results.
The goal was to build a system capable of automatically finding relevant Reddit discussions, extracting useful information, and generating concise answers supported by retrieved context.
Project Objectives
- Build an end-to-end RAG pipeline using n8n.
- Automatically retrieve relevant Reddit discussions.
- Convert Reddit content into searchable vector embeddings.
- Use an AI agent to retrieve the most relevant context before generating answers.
- Produce responses grounded in retrieved Reddit discussions instead of relying solely on the language model.
The Solution
The workflow uses a schedule trigger that runs at a weekly interval. This retrieves the latest reddit posts from specific subreddits using Apify, processes them into searchable embeddings, and stores them in a vector database.
When a user submits a question (e.g. “I need posts wherein users require assistance”), the system performs semantic similarity search against the stored embeddings, retrieves the most relevant discussions, and provides them to the language model as context. The model then generates an answer based on the retrieved information rather than hallucinating unsupported facts.
The entire process runs automatically inside n8n without manual intervention.
Technical Implementation
Workflow Components
- n8n for workflow orchestration
- Apify for reddit search and data retrieval
- Vector database for semantic search
- LLM for Retrieval-Augmented Generation (RAG)
- Prompt engineering to ground responses in retrieved context
- Telegram for chatting and responding to user
Workflows
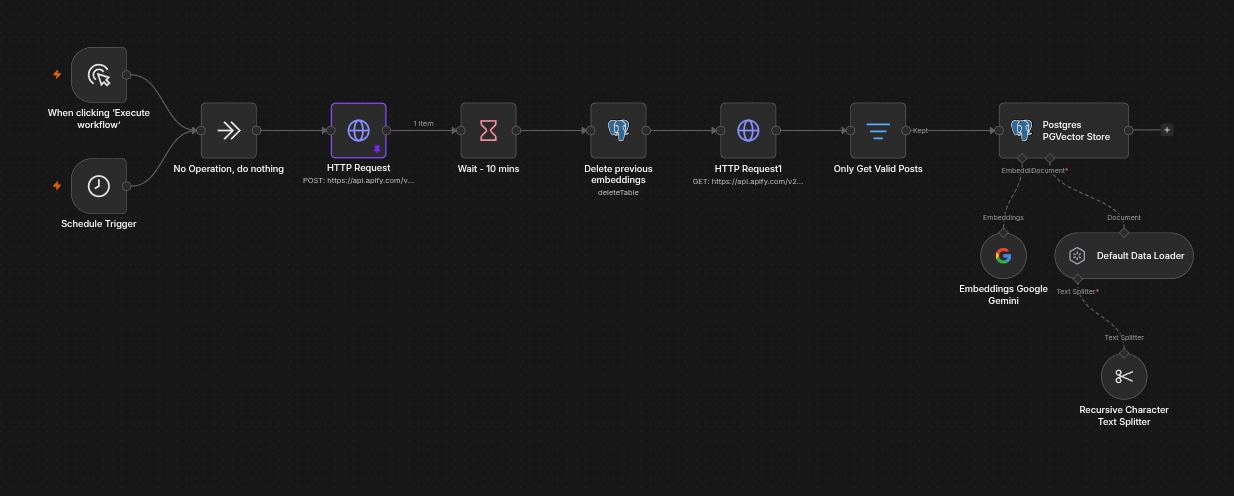
Workflow 1: Search Reddit
- Search Reddit for latest posts from specific subreddits using Apify.
- Retrieve posts.
- Add a safety filter to remove data that is not of data type “post”.
- Generate embeddings.
- Store embeddings in a vector database (in my case, PGVector).
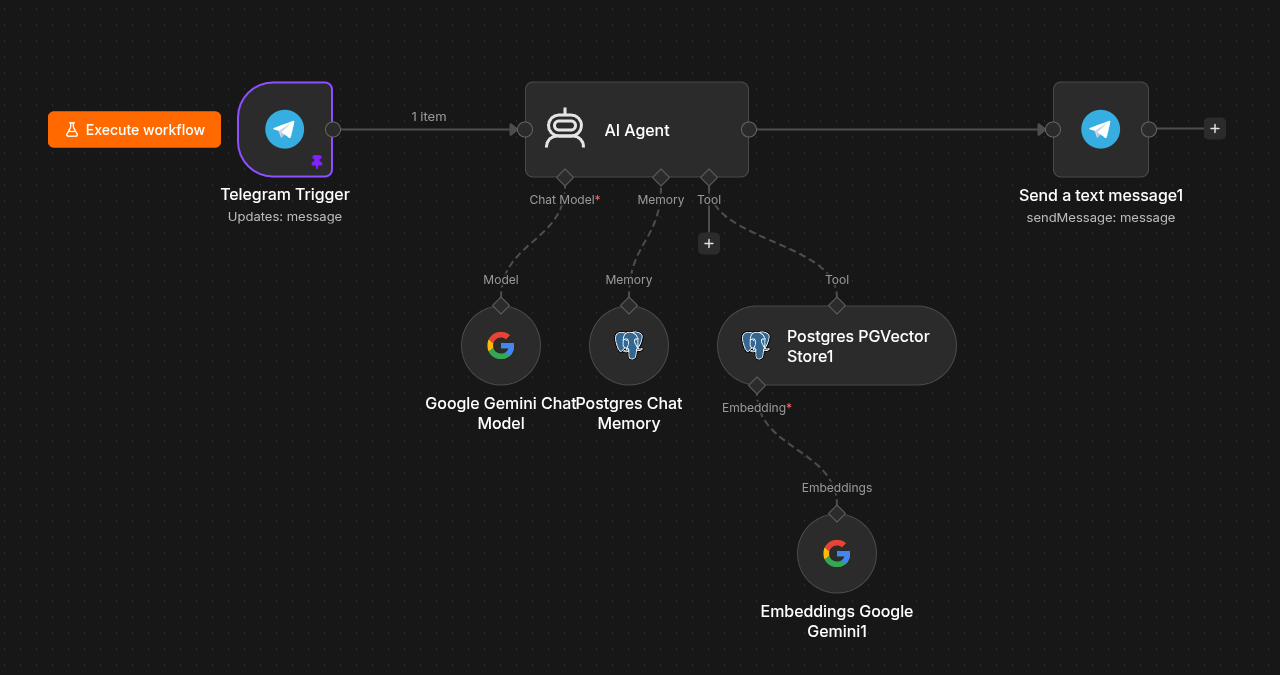
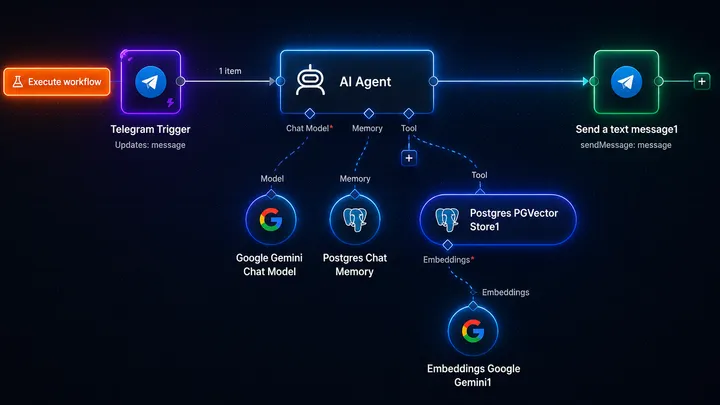
Workflow 2: AI Agent with RAG
- User submits a request.
- The AI agent retrieves relevant posts from the vector database using the pgvector tool.
- The AI agent retrieves the most relevant context from the retrieved posts.
- The AI agent generates an answer based on the retrieved information.
- The AI agent returns the answer to the user.
Challenges
One of the challenges I faced was figuring out how to use the data loader node. Just simply importing the json data into the node wasn’t working because the embedding model was returning empty arrays, which caused the node to fail. I had to modify the data loader node to only embed the title and the body of the post, and add the other fields as metadata. By doing this, I was able to make the data loader work properly and retrieve the relevant data.
Results
- Successfully implemented an end-to-end RAG pipeline using n8n.
- Automatically retrieved relevant Reddit discussions.
- Converted Reddit content into searchable vector embeddings.
- Used an AI agent to retrieve the most relevant context before generating answers.
- Produced responses grounded in retrieved Reddit discussions instead of relying solely on the language model.
Lessons Learned
Building a RAG system involves much more than connecting an LLM to a vector database. Data quality, chunking strategy, retrieval accuracy, and prompt design have a significant impact on the final output.
This project also demonstrated that low-code automation platforms like n8n can orchestrate sophisticated AI workflows while remaining easy to maintain and extend.
Moreover, the project can be extended for other use cases beyond Reddit. For example, we can use the same system to search for relevant trends in the market, or to find relevant news articles. It can also be used to search for relevant images, videos, and documents (e.g. documents containing FAQs, legal documents, and contracts).
Future Improvements
- Maybe add an intent classifier before generating hitting the LLM. This would allow the query to be directed towards the most relevant AI agent or LLM. This would also allow for more complex prompts and better retrieval accuracy.
- Use a more deterministic approach to retrieval. Currently, the system retrieves the most relevant discussions based on the agent’s output. This could be improved by using a more deterministic approach. We could also add query enrichment to the prompt to make the retrieval more accurate.
- Try different RAG design patterns. The system currently uses a naive approach to embedding and retrieval. We could try different design patterns to improve the system’s performance and accuracy.