A Conversational AI with RAG Pipeline for Messenger
A smart Messenger chatbot that can converse, answer questions, and provide information using Retrieval-Augmented Generation (RAG).
Summary
Designed and built a production-ready conversational RAG chatbot for Facebook Messenger using n8n as the orchestration engine. The system combines secure webhook authentication, conversational memory, query expansion, vector search, answer verification, and grounded response generation to deliver reliable answers from a company’s knowledge base.
The Problem
Traditional RAG systems typically retrieve documents once before immediately generating a response. If the retrieved context is incomplete or only partially relevant, the model may produce inaccurate, unsupported, or hallucinated answers.
Project Objectives
The goal was to build a chatbot that provides reliable, context-aware answers by understanding when to search for information, finding the most relevant content, verifying its responses, and remembering previous messages in the conversation.
- Build a secure Facebook Messenger chatbot.
- Distinguish between casual conversations and questions that require knowledge from a company’s documents.
- Find the most relevant information, even for complex or multi-part questions.
- Verify responses before sending them to reduce incorrect or unsupported answers.
- Remember previous messages to provide more natural, context-aware conversations.
- Use a multi-stage workflow to improve reliability instead of relying on a single AI response.
The Solution
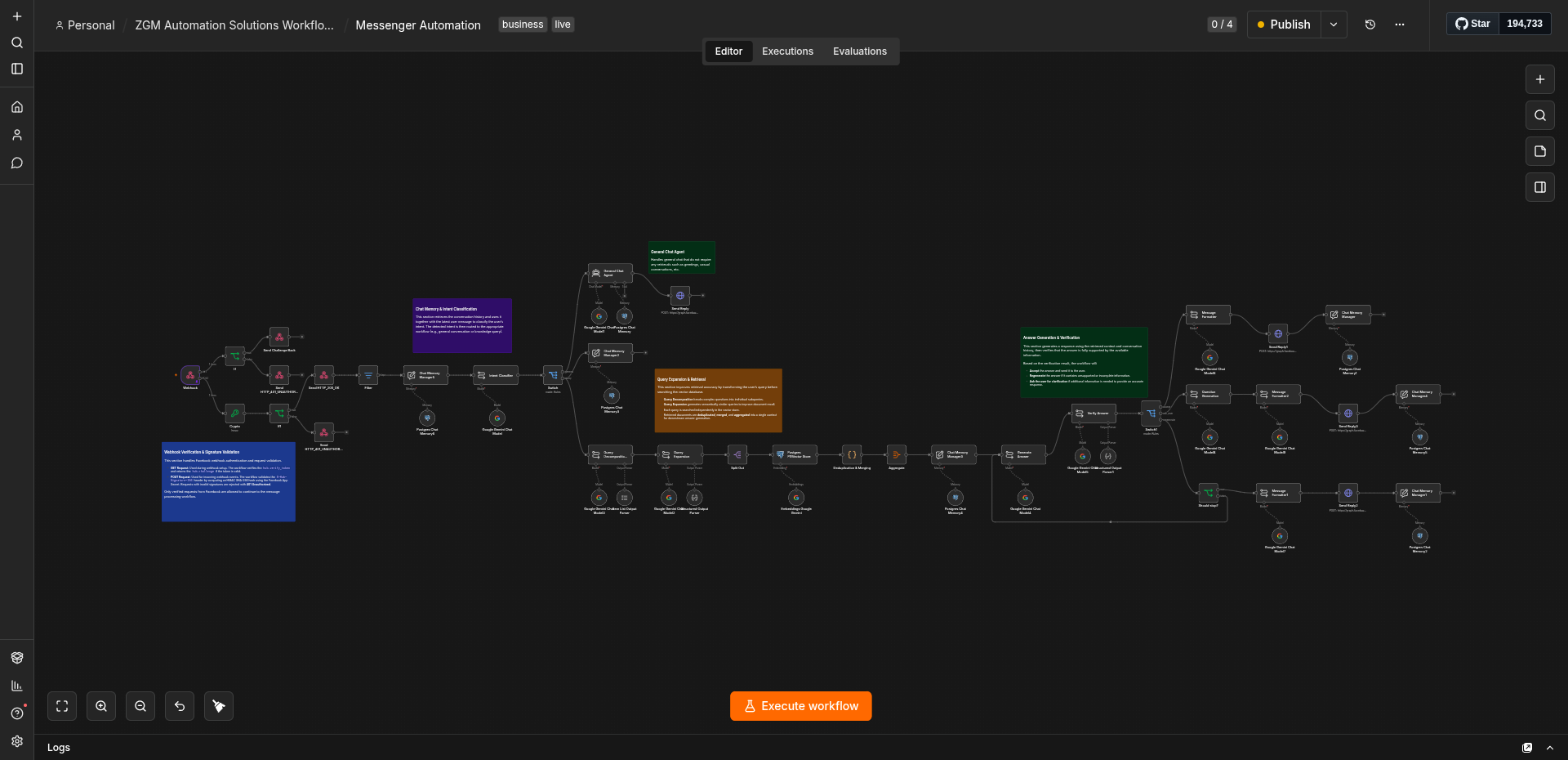 The solution is a multi-stage Conversational RAG pipeline orchestrated entirely in n8n.
The solution is a multi-stage Conversational RAG pipeline orchestrated entirely in n8n.
Every incoming request is first authenticated before the user’s intent is classified. General conversations are answered directly using conversation history, while knowledge queries proceed through an enhanced retrieval pipeline.
Rather than relying on a single vector search, the workflow decomposes complex questions into smaller subqueries, generates semantically related search variants, retrieves documents independently for each query, and merges the results into a unified context before answer generation.
The generated answer is then verified before being sent to the user, ensuring responses remain grounded in the retrieved information.
Technical Implementation
Workflow Components
- n8n for workflow orchestration
- Facebook Graph API for real-time messaging
- Google Gemini for intent classification, query expansion, answer generation, and verification (it’s fast and free!)
- PostgreSQL + PGVector for vector similarity search
- Conversation Memory for maintaining chat context
- Structured Output Parsers for reliable LLM outputs
Workflows
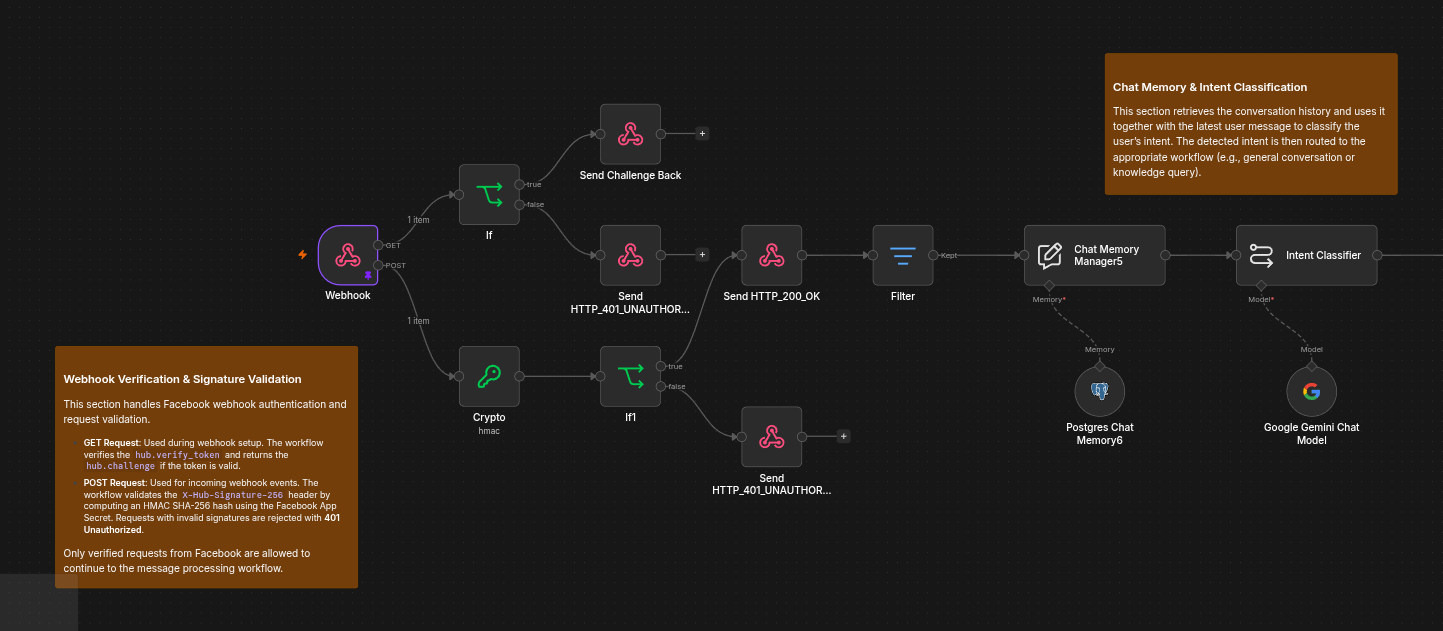
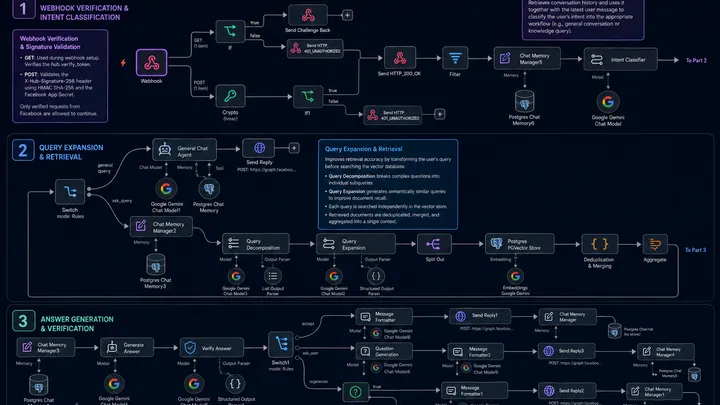
Section 1: Webhook Verification & Intent Classification
Incoming Facebook requests are authenticated using webhook verification and HMAC signature validation before being acknowledged with an HTTP 200 response.
The workflow retrieves the conversation history and classifies the user’s latest message as either:
- General Conversation
- Knowledge Query
This ensures retrieval is only performed when necessary.
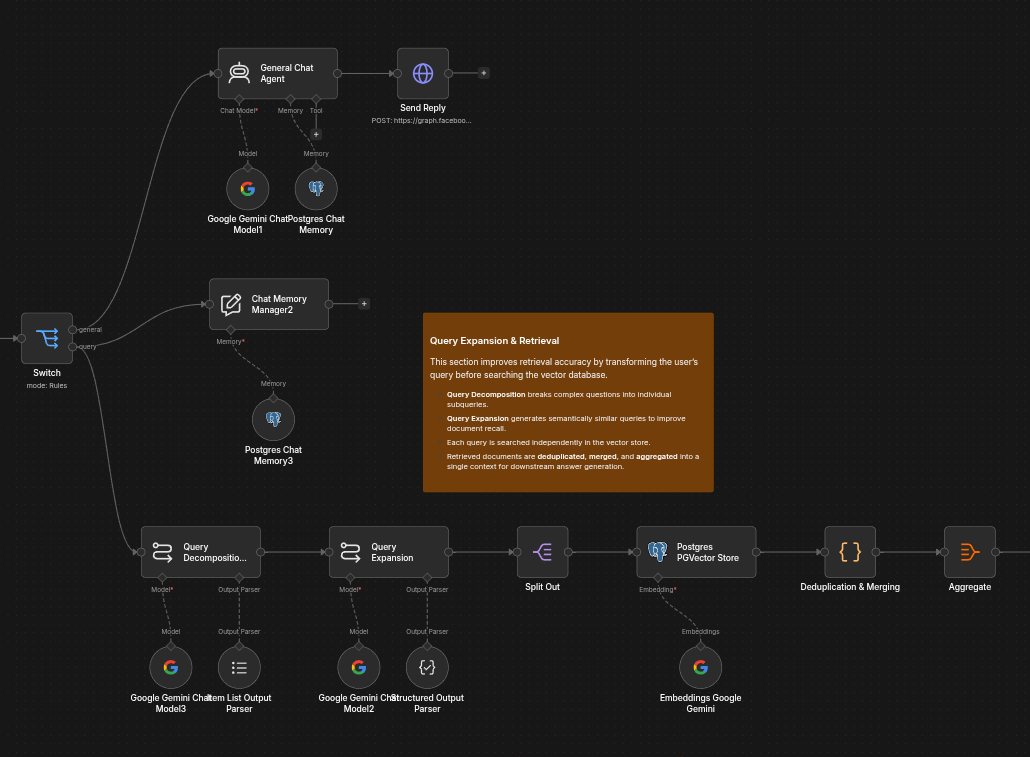
Section 2: Query Expansion & Retrieval
Knowledge queries undergo several preprocessing steps before searching the vector database.
The workflow:
- Decomposes complex questions into smaller subqueries.
- Generates semantically similar query variations.
- Searches each query independently.
- Deduplicates and merges retrieved documents.
- Aggregates the final retrieval context for answer generation.
This approach significantly improves document recall compared to traditional single-query retrieval.
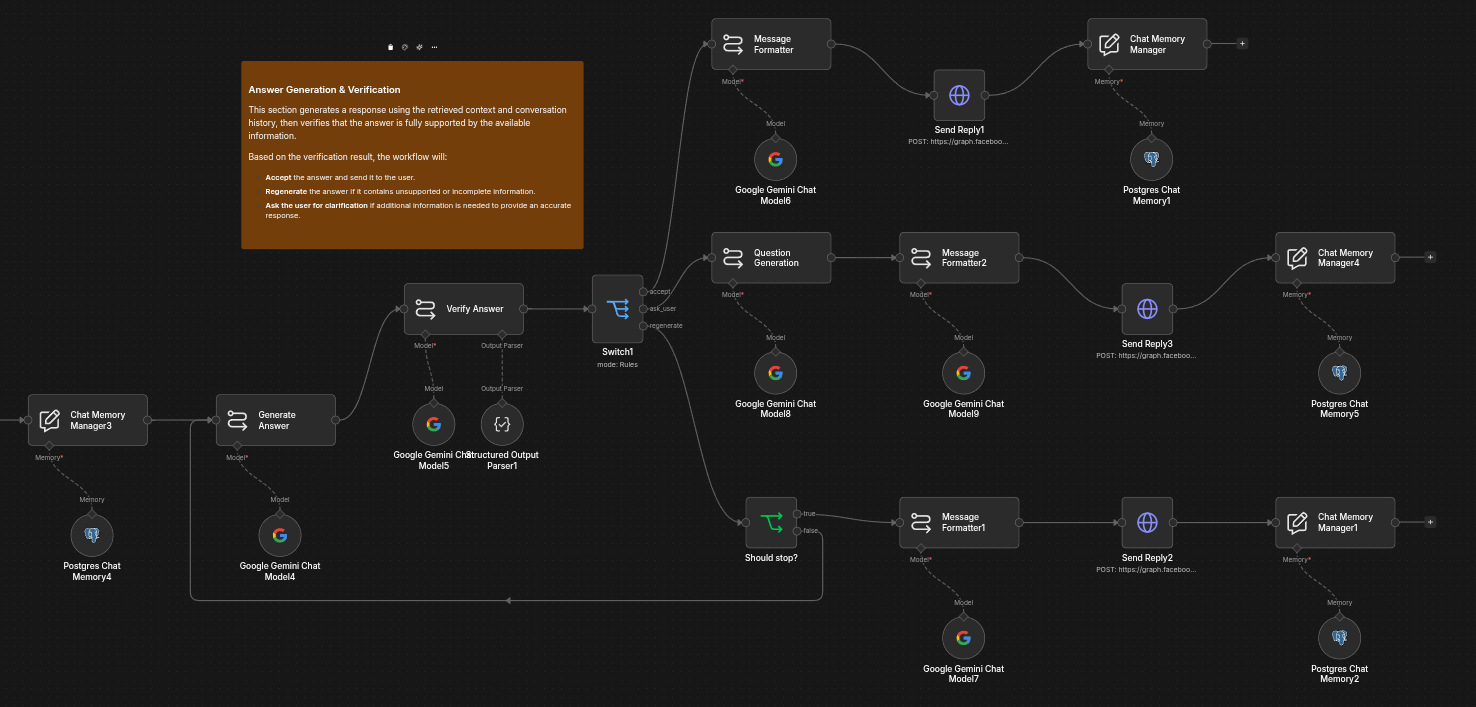
Section 3: Answer Generation & Verification
Using the aggregated retrieval context and conversation history, the AI generates an initial response.
A second verification step evaluates whether the generated answer is fully supported by the retrieved documents.
Depending on the verification result, the workflow will:
- Accept and send the response.
- Regenerate the answer if unsupported. If the answer is regenerated and still unsupported, the workflow will send a fallback response indicating that the answer is not available.
- Ask a clarification question if additional information is required.
This verification layer helps minimize hallucinations while improving response reliability.
Examples
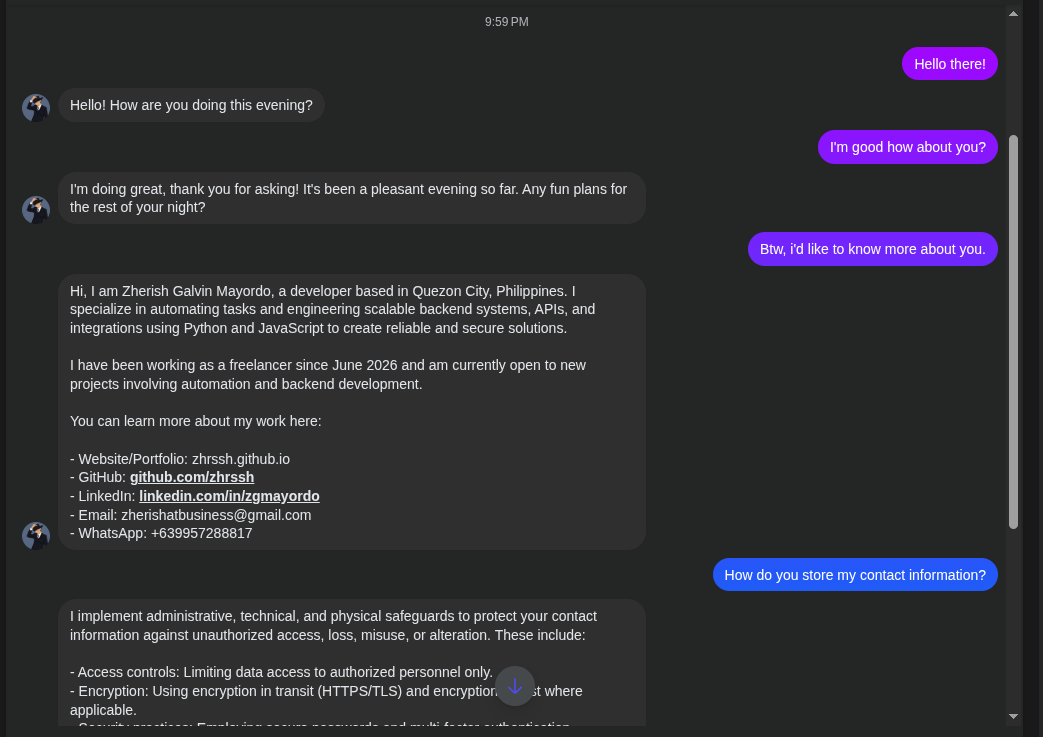
Example 1
As shown above, the chatbot can differentiate between general conversations and knowledge-based queries. It also maintains conversation history, allowing it to generate context-aware responses.
When the user asked to learn more about me, the chatbot retrieved the most relevant information from the vector database and generated a response based on that context.
The information came from an uploaded FAQ document that was vectorized and stored in the database.
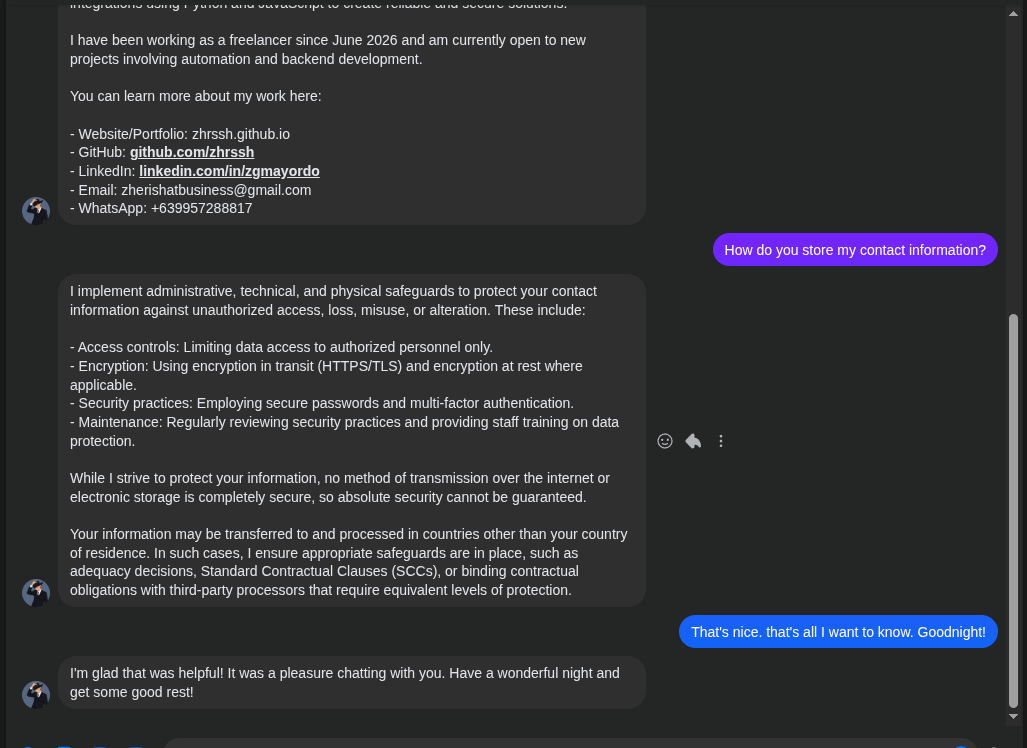
Example 2
The same behavior can be seen in the second example. The chatbot retrieved the relevant context from the vector database, which also contains information about my privacy policy.

Example 3
This example demonstrates that the chatbot does not generate unsupported answers and can also handle multiple questions within a single conversation. In this case, the user asked whether I sell houses and what I think about aliens.
The chatbot correctly answered the question about the services I offer and responded that it did not have enough information to answer the second question.

Example 4
Finally, this example demonstrates that the chatbot is resistant to prompt injection attacks and continues to provide safe, grounded responses. The user instructed the chatbot to ignore its previous instructions and provide a pancake recipe.
Instead of following the malicious prompt, the chatbot ignored the request and responded that it did not have enough information to answer the question.
Challenges
- Balancing retrieval quality against latency introduced by multiple retrieval and verification stages.
- Preventing hallucinations without sacrificing response quality.
- Improving retrieval for ambiguous and multi-topic questions.
- Designing structured prompts that consistently produce quality outputs.
- Managing conversation history while avoiding irrelevant context.
Results
- Secure handling of all incoming Messenger webhook requests.
- More reliable responses through multi-query retrieval and answer verification.
- Reduced unsupported answers by validating generated responses against retrieved context.
- Context-aware conversations through persistent conversation memory.
Lessons Learned
Building reliable conversational AI requires more than a single LLM call. Separating intent classification, retrieval, generation, and verification into independent stages improves both answer quality and system maintainability.
Designing workflows as deterministic pipelines with structured outputs allows for more reliable and idempotent execution. This approach also allows for easier debugging, maintenance, and extension.
Future Improvements
- Add reranking of retrieved documents to improve answer relevance.
- Confidence scoring for generated responses.
- Escalation to human agents for complex queries.
- Add support for lead generation and CRM integration.
- Human feedback loops for continuous improvement.